


现有的AI推理的局限性
在人类的日常生活中,我们并不需要把思维的每一步说出口或画出来才能思考。 比如:你在脑子里可以默默思考一篇文章的结构,或者在脑海中想象一下你家房间的布局。 思考这些都不需要真正动笔或动手去画。
但对于现如今的生成式 AI(比如 GPT-4o DeepSeek这类大型多模态模型)来说,它的“思考”过程本质上是通过“生成东西”来完成的。也就是说,它并不是像人类一样,在内部默默推理、默默构图,而是在每一步都必须“写出字”或“画出图”来辅助自己完成思考。
假设你问一个 AI:“这把椅子从不同角度看起来是什么样子?”
🧍人类的处理方式: 我们会在脑中想象那把椅子的三维结构,然后“脑补”它旋转后的样子。我们不需要真的画出来,靠大脑内的“心理图像”就可以完成。
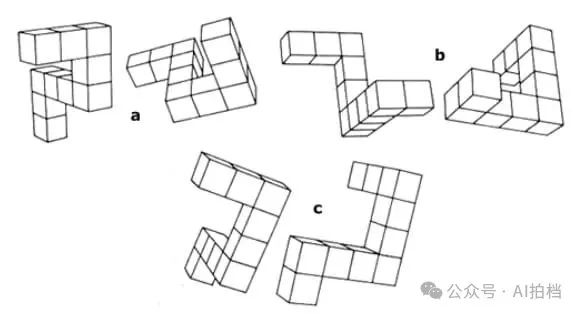
🤖 AI 的处理方式(传统多模态模型): AI 可能会通过逐步生成一张旋转后的椅子图像,然后再用这张图来推理下一步。它不是“在脑子里转椅子”,而是每转一个角度就得画一张图出来,再继续想。 换句话说,生成本身就是它的一部分思考过程。
直到 Mirage 的出现,这种局限才被打破。
但问题是——我们为什么需要让机器拥有这种像人类的思考能力?
人类想象的能力
几十年来,科学界已经明确知道:人类在大脑中会生成带有图像特征的 “心理图像”(mental images),这些图像具有类似视觉图画的表征形式。
为了避免过多术语,我们简要回顾一下。早在 1994 年,Stephen Kosslyn 就通过一系列研究证实,人类确实会在头脑中构建“心理图像”。
科学家在研究中发现:人类在心中旋转物体图像时,所需的反应时间与旋转角度成正比。这强有力地证明了人脑中的图像处理不仅仅真实存在,而且具有空间操作性——我们的大脑并非抽象地“理解”图像,而是在“心中看见并操纵”它们。
这个发现说明,我们头脑中的图像表征是具有空间属性的。因为人在进行这种心理旋转时,其实是在主动地从一个新的角度重新构建图像。
我们在思考场景时,并不是以符号的方式进行抽象推理;我们是在大脑中真实地构建出这些场景的画面。
所以,如果人类会在脑中构建心理图像,并且这一能力很可能正是我们进行空间推理的基础,那为什么人工智能不应该也具备同样的能力呢?
什么是潜在空间(Latent Space)
在现代人工智能中,几乎所有核心机制都围绕着一个概念展开:内部表征(internal representations)。
这些“表征”并不是文字、图像或声音,而是一些数值向量(vectors) 毕竟机器只能处理数字。这些向量所承载的,是模型对现实世界中各种概念的理解。这是什么意思?
在 AI 的世界里,理解不是通过“定义”来建立的,而是通过“相对相似度”来形成的。用一句更通俗的话说:
AI 理解“猫”这个概念,并不是因为它知道“猫的本质是什么”,而是因为它知道“猫”与“狗”“老虎”等概念之间比较相似, 而与“航空母舰”之类的概念差异极大。
也就是说,模型是通过“和其他概念的距离关系”来理解一个概念的意义。
通过这种方式,模型在内部构建出一个被称为 “表征空间”(representation space)的结构,更正式的说法叫做“潜在空间”(latent space) 。
比如在潜在空间中,“猫”与“狗”或“老虎”等概念距离非常接近,因此模型会推断出:“猫”属于“动物”这一大类。而更进一步,由于“猫”与其他哺乳动物之间的距离也很小,模型进一步判断出,“猫”不仅是动物,还是属于“哺乳动物”这一子类。
这个潜在空间本质上是一个高维向量空间,它就是模型的“知识地图”。在这个空间中:
- 每一个概念都是一个点(向量);
- 点与点之间的距离表示它们的语义差异;
- 一个概念的“意义”,就是它在整个空间中的相对位置。
因此,模型所“知道”的一切,不管是“猫”还是“航母”。都是通过在这个潜在空间中彼此定位、比较和联系来实现的。
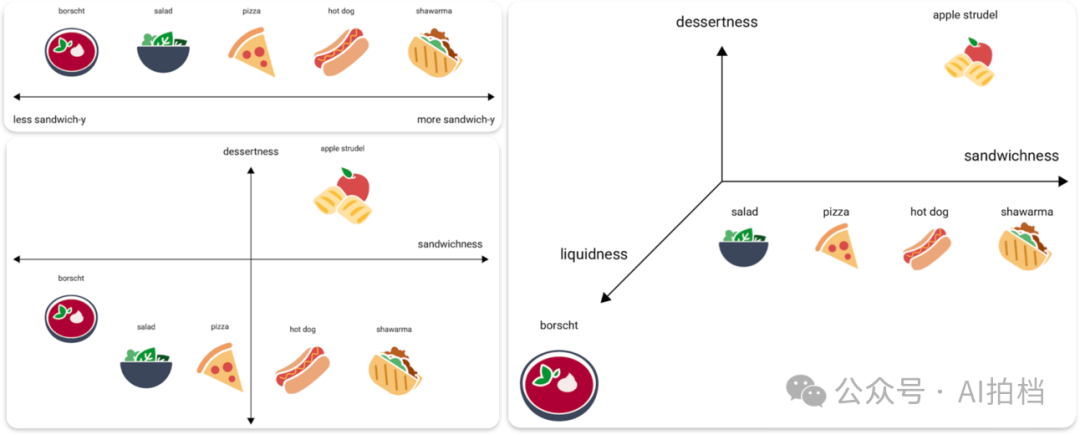
这也正是 AI 推理和生成的基础。
因此,每当模型接收到新的输入——无论是文本、图像,还是二者的结合。它都会将这些信息映射到潜在空间中,并依赖这种空间结构来理解“输入的内容是什么”以及“下一步应该生成什么”。
然而,尽管这些模型被称为 “多模态模型”(multimodal) ,它们的核心处理机制仍然严重依赖 “文字思维”(text thinking) 来生成响应。那么,什么是“文字思维”?我们为什么说它是个问题?我们接着往下看。
从“纯文本”到真正的多模态智能
假设你现在看到下图中的问题,你会如何解答这些题目?(规划一个路线,让小人拿到奖励,并且不掉进洞里):你会在脑中想象路径的走向。你甚至可以脑补出手指在图上移动的样子,或是路径被高亮的样子。
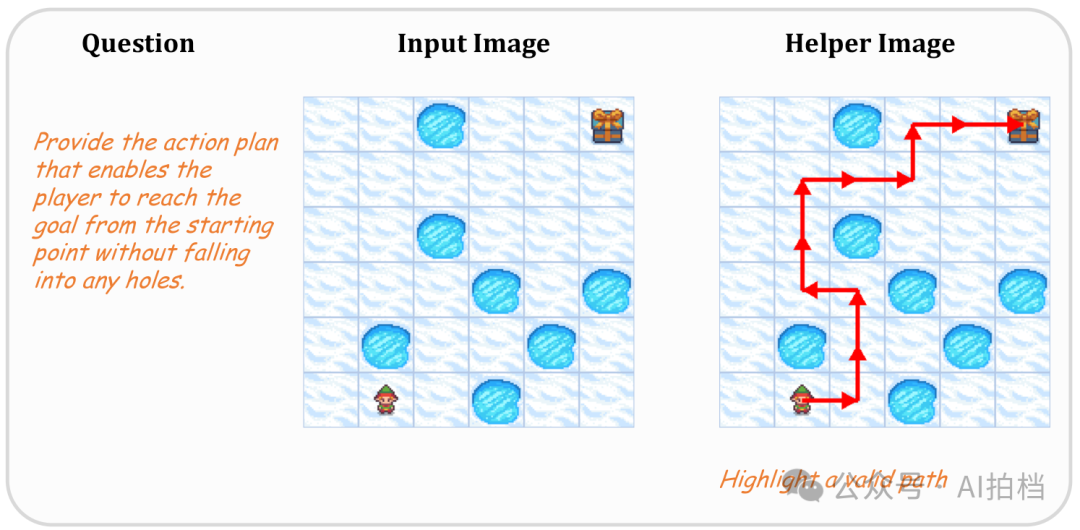
AI 是怎么解决同样问题的?
AI不会“想象”那条路径长什么样,也不会在脑中模拟走法。它会把图像转化成一堆“结构化信息”或者“文字描述”,比如说:“图上有一个起点 A,终点 B,错误点位于一行三列,路径方向是…”(像DeepSeek的思考过程)然后用一堆“逻辑推理 + 语言模型”来生成答案。
造成这一现象的技术原因主要有两个:
首先,如前所述,AI 模型在“思考”时必须生成内容——说出文字、绘制图像,或者两者都有。它们并不存在某种“中间状态”,可以让模型在不输出任何东西的前提下,随意“思考”。对它AI来说,生成本身就是思考的必要步骤,只有通过生成,问题才能被解决。
其次,使用图像进行思考,或者说生成图像以辅助推理,对于用户而言是一种非常糟糕的体验(主要因为速度极慢)。因此,当前最前沿的模型在大多数情况下选择回避图像生成,而改用文本来处理问题。也就是说,即使任务本身明确需要视觉思维,模型最终还是会主要依赖文本,甚至是代码来寻找解法。
那么,我们要如何才能赋予 AI “心理图像”这样的能力呢? 这正是当前研究的关键所在。
现有核心思路是:训练模型识别出何时需要进行视觉化思考,并在那一刻生成一个特殊的标记 token,将模型引导进入“空间思维”模式。此时,模型将在潜在空间中进行视觉推理,而不是切换回文字空间。等到视觉思维阶段结束后,模型再重新回到文本生成的轨道,继续输出结果。这听起来有些玄幻,但现在很多研究团队都在这方面努力。

麻省理工学院和阿默斯特学院的研究人员最近发表了一篇全新的论文。他们提出了一种名为 Mirage 的AI模型,它是首个真正具备“视觉思维”能力的模型。这意味着它能够像人类一样,在大脑中构建“心理图像”。
让模型在输出答案之前先进行内部思考,是当前研究领域的一个热门方向。 这样做的好处在于:它可以减少生成的 token 数量(降低成本),并且这种“先思考、后表达”的过程也更贴近人类的行为方式。
但问题在于:它的这种内部思考依然是以文字为主的。换句话说,模型虽然没“开口说话”,但它的思维过程依然建立在语言上,而非真正的心理图像。
为了解决这个问题,Mirage 的研究人员设计了一套独特的“视觉数据集”:其中包含由人工标注的辅助图像,作为模型解题的参考。 简单来说,这种训练方式强迫模型利用图像中的视觉线索来推理并给出答案,而不是仅依赖文字或代码推导过程。
论文地址:https://arxiv.org/abs/2506.17218
此外,为了证明模型确实在学习并利用视觉线索,研究团队还进行了主成分分析(PCA, Principal Component Analysis)。 结果显示,当模型处理视觉场景时所生成的新的潜在思维(latent thoughts)的分布与图像处理阶段学到的图像潜在分布非常接近,并且在潜在空间中呈现出高度聚集、紧密分布的特征。
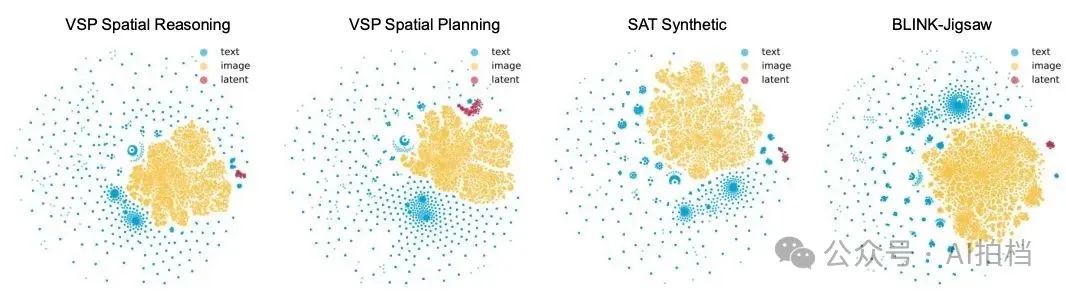
相比之下,传统的文本潜在表示则通常在模型主导的文本空间中均匀分散分布。这一差异说明:模型在进行“视觉思考”时,确实进入了一种更接近图像表征的内在思维状态,而不再只是“用语言假装理解图像”。正如预期的那样,Mirage在各类空间推理与规划基准测试中都表现出显著提升。这表明,这种方法不仅在理论上讲得通,在实际效果上也确实奏效。
文章来自:51CTO

