


人工智能赋能制造业,通过提高良率、降低原材料损耗等方式降低生产成本,提高生产效率;另一方面,通过更快的CPU,更强劲的算力推动制造业加速升级和转型
21世纪,最贵的除了人才还有什么?那就是算力!算力!还是算力!随着数字经济的蓬勃发展,各行各业面临生产力的短缺。为了解决这一现状,越来越多的行业转向了自动化。在这个过程中,各种人工智能的应用案例屡见不鲜,人工智能不再只是停留在论文里,而是已经有了丰富的商业落地案例。其中有两个案例给我的印象很深刻
算力在制造业的落地
第一个案例就是算力发展在制造业的体现。
不论是手机还是电脑,各类电子设备都有一个非常重要的人机交互元件:屏幕。屏幕相关的产品线涵盖了 TF T-LCD、AMOLED 等一系列先进显示和传感器件,这些产品无一不对质量有着严苛的要求。随着产业规模的不断扩大,基于人工的缺陷检测和不良根因分析,在效率上已经难以满足进一步提升产能和品控的要求。现在基于深度学习来协助实现缺陷定位和缺陷检测等功能的工业视觉平台,能够借助大数据平台和AI算法,智能分析和快速定位不良根因。
英特尔® 至强® 可扩展平台在边缘加速 AI 缺陷检测
「缺陷检测」是屏幕、传感器等精密器件生产中的关键环节,之前一直依靠人工检测,然而人工检测存在很多不足,一般主要包括人才的培养费时费力,其次是检测准确率相对较低,随着工艺飞速发展,涉及的缺陷类型越来越多,且许多已经很难用肉眼发现。
曾经为了解决这个问题,企业需要培训和安排大量检测工程师来确保产品质量。但现在可以借助英特尔边缘计算的能力,通过研发基于深度学习方法的自动化缺陷分类 (Automated Defect Classification, ADC) 系统,来提升缺陷检测效率。在新的 AI 缺陷检测系统中,历史积累的图像以及由自动光学检测 (Automated Optical Inspection,AOI) 等设备采集的图像,都会由边缘服务器预处理后汇入数据中心,并使用 ResNet、Faster-RCNN 等图像检测和分类算法进行训练,输出的模型会被部署到边缘服务器中。新 AI 缺陷检测系统上线部署后,可大幅提升检测准确率并降低人力成本,真正实现降本增效。
算力在医学辅助诊断领域的落地
得益于算法的进化、算力的提升,AI 辅助诊断得到了广泛的应用。然而,AI 辅助诊断应用由于对 IT 基础设施有着较高要求,在实际落地中面临着硬件成本、软件优化和方案整合等挑战。
AI 应用于医学诊断,主要还是通过利用医学影像进行辅助诊断。近几年, CT 的临床诊疗应用直接凸现了影像检查的重要性。通过英特尔 OpenVINO™ 工具套件可加速阅片效率。该工具套件基于卷积神经网络 (CNN) 而设计,支持从边缘到云的深度学习推理,可以在所有英特尔平台上部署并加速神经网络模型,显著提高图像推理速度。由此可快速构建、优化和积累高质量的样本数据和认知模型,为医疗专业人员与 AI 技术专业人员协作搭建创新的平台,全面优化模型推理效率。利用定制的 DNN 拓扑来识别影像、通过支持多种病理切片数据的接入来实现病理图像的数字化诊断与分享,这些能力让病理诊断业务拥有远程会诊、集中诊断等更多延展空间,为医生阅片提供参考。
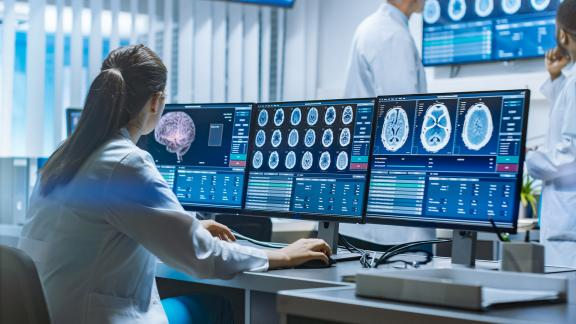
可见算力已经深入到生产生活的方方面面,可以预计的是,人类生活未来必然越来越离不开算力,而高性价比地获取算力也将成为商业成功的重要部分。
英特尔® 至强® 可扩展处理器算力赋能,加速AI推理过程
提到 AI 的推理,大家的第一反应可能是需要强大的GPU。但实际上,经过多年的发展,CPU同样可以加速推理过程,且性价比更高。像英特尔® 至强® 可扩展处理器,内置了人工智能计算和高级安全功能,依靠其强大算力可以极大提高AI推理效率,并兼顾成本与安全性。
为了在 CPU 上实现优秀的 AI 推理能力,英特尔从底层指令集的设计,到矩阵运算加速库,再到神经网络加速库都进行了专门的优化。
CPU 指令集是计算机能力的核心部分,英特尔® AVX-512 指令集旨在提升单条指令的计算数量,从而提升 CPU 的矩阵运算效率。在加速训练环节,英特尔® DL Boost 把对低精度数据格式的操作指令融入到了 AVX-512 指令集中,即 AVX-512_VNNI (矢量神经网络指令) 和 AVX-512_BF16(bfloat16),分别提供了对 INT8(主要用于量化推理)和 BF16(兼顾推理和训练)的支持。
了解了基本原理后,我们再来看使用 CPU 训练模型的优势就很明显了:在只使用英特尔® 至强® 可扩展处理器的情况下,内存可以便捷地根据需要扩充,同时也可以根据任务和场景分配计算核心,这样的灵活性是其它硬件很难具备的。
另外,在企业中部署 AI 模型,CPU 服务器同样常用。大多数 AI 实际要求的是并发量,对推理速度没有特别高的要求;而且制造业或图像行业的模型也不会太大,这种情况就很适合使用 CPU 作为计算设备。
在执行上线部署时,常见的推理引擎部署工具就有 OpenVINO™(Open Visual Inference & Neural Network Optimization,开放视觉推理及神经网络优化)。它是英特尔基于自身现有硬件平台开发的工具套件,用于加快高性能计算机视觉和深度学习视觉的应用开发速度,具有专属为 CPU 优化的特质。目前已广泛应用在工业、零售、辅助诊疗等领域。
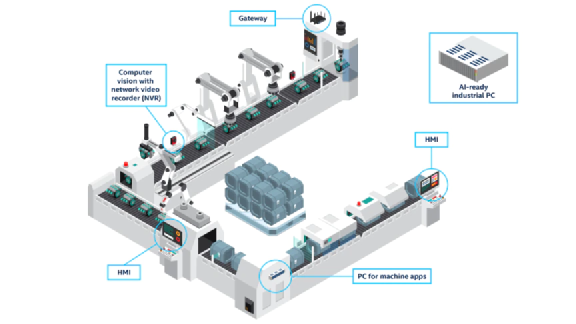
图:在制造业中,至强可扩展处理器可作为边缘计算设备,也可为多功能平台提供基本计算能力,以支持各种 AI 场景与模型。
关于更多英特尔CPU加速带来的好处,感兴趣的可以看看下面这个视频~
此外呢,学术界也有一个研究方向就是轻量级神经网络,目标是使用较少的参数和较低的算力达到同样性能与效果。例如百度提出的PP-LCNet,一个能够在 CPU 上训练的深度学习网络模型,总结起来改进了 4 点:
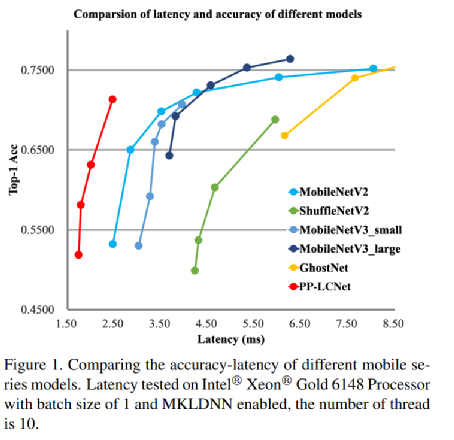
图 PP-LCNet 轻量级 CPU 卷积神经网络
随着学术界研究地不断深入,随着工业界不断的优化,用CPU训练轻量级神经网络将可能是一个性价比颇高的选项,CPU相比GPU减少了训练数据在和内存中的反复转移,使得CPU训练轻量级神经网络更高效。各种重要的是训练这些轻量神经网络使用CPU就足够了,而GPU显得“杀鸡焉用牛刀”,同时成本却远高于CPU。

随着我国大力提倡推动云平台的发展,结合英特尔边缘计算带来的优势,利用 5G、人工智能、高性能计算、大数据分析等新技术,探索更多应用场景,不仅推动制造行业的智能化转型还促进了医疗领域的信息共享和智能化发展。



